(46)王道数据结构-图的深度优先遍历
基本概念
深度优先搜索类似于树的先序遍历。首先访问图中某一起始顶点v,然后由v出发,访问与v邻接且未被访问的任一顶点w1,再访问与w1邻接且未被访问的任一顶点w2·····重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直到图中所有顶点均被访问过为止。
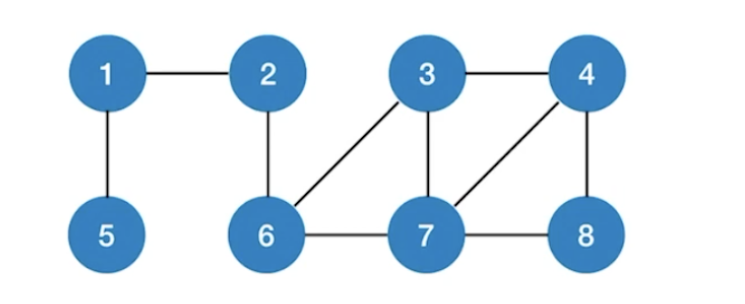
从2出发深度优先遍历序列: 2, 1, 5, 6, 3, 4, 7, 8
1 | |
最终版(DFS)
解决了非联通图问题
1 | |
1.图的邻接矩阵表示是唯一的,但对于邻接表来说,若边的输入次序不同,生成的邻接表也不同。
2.因此,对于同样一个图,基于邻接矩阵的遍历所得到的DFS序列和BFS序列是唯一的,基于邻接表的遍历所得到的DFS和BFS序列是不唯一的
复杂度分析
空间复杂度
DFS算法是一个递归算法,需要借助一个递归栈,故其空间复杂度为O(|V|)。其中函数调用栈道最坏情况,递归深度为O(|V|)
。最好情况时间复杂度为O(1)
时间复杂度
时间复杂度 = 访问各结点所需时间+探索各条边所需时间
1.用邻接矩阵表示,访问|V|个顶点需要O(|V|)的时间,查找每个顶点的邻接点都需要O(|V|)的时间,而总共有|V|个顶点,时间复杂度为O(|V|^2)
2.用邻接表表示,访问|V|个顶点需要O(|V|)的时间,查找各顶点的邻接点共需要O(|E|)的时间,时间复杂度=O(|V|+|E|)
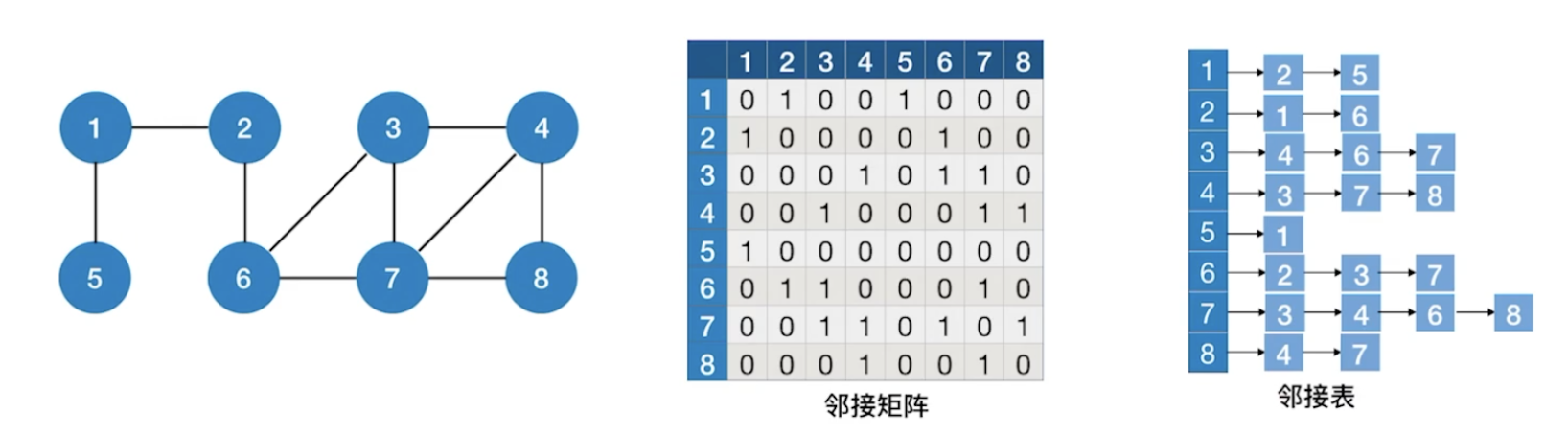
从2出发的深度优先遍历序列: 2, 1, 5, 6, 3, 4, 7, 8
从3出发的深度优先遍历序列: 3, 4, 7, 6, 2, 1, 5, 8
从1出发的深度优先遍历序列: 1, 2, 6, 3, 4, 7, 8, 4
深度优先生成树
对连通图调用DFS才能深度优先生成树,否则产生的将是深度优先生成森林。
1.同一个图的邻接矩阵表示方式唯一,因此深度优先遍历序列唯一,深度优先生成树也唯一
2.同一个图邻接表表示方式不唯一,因此深度优先遍历序列不唯一,深度优先生成树也唯一
graph TD;
A(("1"));
B(("2"));
C(("3"));
D(("4"));
E(("5"));
F(("6"));
G(("7"));
H(("8"));
B-->A;
B-->F;
A-->E;
F-->C;
C-->D;
D-->G;
G-->H;
生成森林
graph TD;
A(("1"));
B(("2"));
C(("3"));
D(("4"));
E(("5"));
F(("6"));
G(("7"));
H(("8"));
I(("I"));
J(("J"));
K(("K"));
B-->A;
B-->F;
A-->E;
F-->C;
C-->D;
D-->G;
G-->H;
I-->J;
J-->K;
遍历与连通
无向图
对于无向图,若无向图是连通的,则从任一结点出发,仅需一次遍历就能够访问图中的所有顶点;若无向图是非连通的,则从某一个顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。
调用次数:
1.对于无向图进行BFS/DFS遍历,调用BFS/DFS函数的次数 = 连通分量数
2.对于连通图,只需调用1次BFS/DFS
有向图
对于有向图,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有顶点。
调用次数:
1.若起始顶点到其他各顶点都有路径,则只需调用1次BFS/DFS函数
2.对于强连通图,从任一结点出发都只需调用1次BFS/DFS
3.在BFSTraverse()或DFSTraverse()中添加了第二个for循环,再选取初始点,继续进行遍历,以防止一次无法遍历图的所有顶点。
对于无向图,上述两个函数调用BFS(G, i)或DFS(G, i)的次数等于该图的连通分量数;而对于有向图则不是这样,因为一个连通的有向图分为强连通的和非强连通的,它的连通子图也分为强连通分量和非强连通分量,非强连通分量一次调用BFS(G, i)或DFS(G, i)无法访问到该连通分量的所有顶点。